- Celebreren of removeren? Frans in de Leidse Resolutiën
- Wetenschap die gebeurt als je andere plannen had
- Eylaci, een vreemd woord
- MNL Fellowship: Eindelijk een baan in een bibliotheek (en wat ik daar voor onderzoek ga doen)
- Slauerhoff aan de Zwarte ZeeJos Versteegen
- Alweer een generaalVilan van de Loo
- Altijd reuringMichiel van Kempen
- Zere vingerLiesje Schreuders
- LevensechtNicolette Smabers
- De sfinx spreektMario Molegraaf
- Het geliefde huisdierVilan van de Loo
- De boekenkisten van Eddy du PerronTom Phijffer
- Bakkes’ ballingschapRody Chamuleau
- Den Haag: van Kota Senang tot Weduwe van IndiëCoen van ’t Veer
 Volg ons op X
Volg ons op X
 Volg ons op Bluesky
Volg ons op Bluesky
 Volg ons op Facebook
Volg ons op Facebook
Wie tekstverzamelingen bestudeert, kan beginnen bij de meest basale en oppervlakkige manier van observeren: kijken welke woorden het meest voorkomen. Over het algemeen komt daar al heel snel hetzelfde lijstje uit: de, het, een, ja, ik, niet maar en aanverwanten. Functiewoorden scoren nou eenmaal altijd véél hoger dan inhoudswoorden. Maar als je wat verder door zo’n lijstje loopt, dan valt je toch al snel een of ander op. Mijn verzameling van Leidse Resolutiën is hierop geen uitzondering.
Afbakening
Eerst kort nog iets over mijn dataverzameling. Ik was van plan data te verzamelen uit zes tijdvakken, in stappen van vijftig jaar vanaf 1550-1599 tot en met 1800-1849. De bedoeling was om voor ieder tijdvak de officiële Resolutiën na te lopen op teksten die daar werden gereproduceerd van een origineel, bijvoorbeeld een memorie of een ingekomen brief. Inmiddels is duidelijk dat deze praktijk in ieder geval na 1750 niet meer voorkwam. In materiaal na dat jaar wordt namelijk slechts verwezen naar de originele teksten: "zie requeste in Bijlagen". Zo valt er dus al een derde van mijn onderzoeksobject af, maar goed, zo is de wetenschap. In mijn promotie bijvoorbeeld richtte ik me in eerste instantie op de periode 1804-2000, maar viel al snel de hele negentiende eeuw af.
Voor de ander vier tijdvakken heb ik wel dubbele versies gevonden en gefotografeerd. Die data moet ik nu transcriberen. Dat gaat vrij traag, omdat mijn leesvaardigheid van oude teksten niet zo goed is. Gelukkig wordt het beter, onder andere doordat ik fijn kan oefenen op de geweldige website van Wat Staat Daer. Ik heb nu de teksten uit de periodes 1610-1649 en 1700-1749 af. Dat gaat om respectievelijk 4856 en 3657 woorden. Als corpus stelt het qua omvang weinig voor, maar de ervaring leert dat voor het type spellingsverschijnsel waar ik naar op zoek ben (verandering van -ae- naar -aa- bijvoorbeeld, of van -ck naar -k) deze hoeveelheden voldoende zijn. Maar eerst keek ik dus even naar welke woorden het meest voorkwamen in deze tijdvakken.
Lijstjes
Een frequentielijstje uitdraaien is makkelijk, met behulp van concordantieprogramma’s als AntConc en #Lancsbox. Als ik dat doe voor mijn twee tekstverzamelingen, dan levert dat het volgende op:
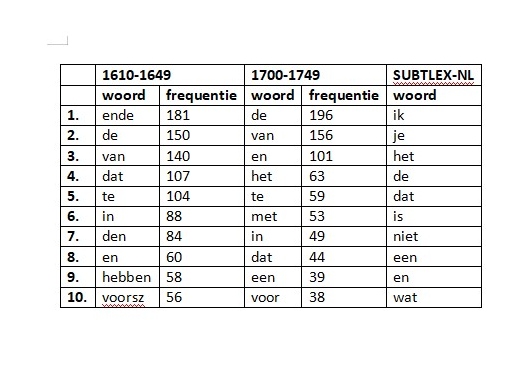
Zoals ik al zei: het zijn bijna altijd functiewoorden. Vergelijken we dit lijstje echter met de top 10 van SUBTLEX-NL, dan zien we toch wat verschillen. Dat corpus bevat ondertiteling van film en tv, die vooral dialoog zal zijn. Logisch dus dat daar persoonlijke voornaamwoorden hoger scoren. De teksten in de Resolutiën spreken daarentegen vaak van wat Burgemeesters en Curateurs hebben besloten (zie ook meteen de hoge score voor hebben). En er is nog wel een en ander op te merken over deze lijstjes.
Zo valt het meestvoorkomende woord ende in 1600-1649 op, dat in 1700-1749 was gezakt naar plaats 12 met 36 voorkomens, ten gunste van en. Deze omwenteling is een typisch voorbeeld van de transitiefase waarin het Nederlands zich bevond in de zestiende en zeventiende eeuw, en waarin Middelnederlandse taalelementen verdwenen. Overigens is het altijd leuk om te kijken of de relatieve aanwezigheid van deze voegwoorden is veranderd, omdat dat kan wijzen op een verschil in schrijfstijl (tussen parataxis en hypotaxis, maar dat terzijde). Tellen we ende en en op, dan komt dit in 1600-1649 in 1 op de 20 woorden voor, en in 1700-1749 zelfs 1 op de 26. Een toename dus, niet wereldschokkend, maar wel goed om altijd even naar relatieve aanwezigheid te kijken.
Opvallend
In 1700-1749 staan ook met en voor in de top 10. Dat lijkt een voorbeeld van het zogenaamde karakolprobleem, waarbij een woord vaak voorkomt afhankelijk van de tekst. In dit geval worden met en voor vaak gebruikt in één tekst uit 172 waarin het menu van het College werd besproken, en waar herhaaldelijk sprake is van een gerecht dat voor af wordt gegeten met jeu bijvoorbeeld. Overigens gaat het bij het karakolprobleem meestal om inhoudswoorden, maar hier niet, hoewel boter met twaalf keer vrij hoog scoort. Men at namelijk bijna altijd ’boter na’, zoals wij dat nu doen met yoghurt. Pure boter, ik moet er niet aan denken... Maar ook dat geheel terzijde.
Het meest opvallende woord is voor mij zeker voorsz, dat met 56 voorkomens op plaats 10 staat in 1600-1649. Dit is een afkorting van ’Voorschreven’, en is een woord dat in SUBTLEX-NL slechts 1 keer voorkomt... op 50 miljoen woorden! Niet zo gek als je je realiseert dat het een kenmerk is van zeer formeel en/of juridisch taalgebruik, en ook nog van geschreven taal (het is niet voor niets voorschreven), die in het corpus van ondertiteling nauwelijks voorkomt. In die formele en geschreven context komt het trouwens nog steeds voor, zoals te zien is in dit Kamerstuk.
Het stelt allemaal niet veel voor, maar toch is het leuk om te zien dat zelfs dit soort ogenschijnlijk voor de hand liggende lijstjes interessanter zijn, naarmate je dieper in de materie duikt. Ik ga terug naar het transcriberen van mijn materiaal: misschien dat de andere tijdvakken nog weer andere dingen laten zien...